As a programmer, I constantly hear the siren’s cry of meta modelling. Programming is all about building abstractions to represent reality. By inference, being able to abstract these abstractions results in an “application generator” (or meta application) which can be used for any purpose. Some may call this the holy grail of programming.
At least that’s the theory.
In my line of work, I have been fortunate enough to take part in the implementation of two such meta models (or “master” patterns if you will).
- Soft-coded values (anything attribute)
- Anything Relationship (accountability)
Soft-coded values (anything attribute)
The soft-coded values pattern is best explained by: Blaha & Smith (2002).

The model above addresses the following weaknesses in current relational databases:
- No support for inheritance
- It is difficult to change the entities and attributes in the database on the fly
- No support for keeping a history of values
It addresses most of these weaknesses by storing a good deal of mete data in the actual database. This meta data is “soft coded” and can thus be changed easily with no change to the database schema or the business logic (although the authors admit the user interface will have to be changed).
Anything Relationship (accountability)
This pattern grew out of thinking about Martin Fowler’s accountability pattern.
The accountability pattern goes as follows.

Once again, we are storing meta data. This time the meta data relates to the types of Parties and the types of Accountability they can enter into. It also relates to a connection rule which constrains which types of parties can have which types of accountabilities.
By abstracting the accountability pattern as far as we can go, we get the anything relationship pattern. Note that the anythings enter into relationships with other anythings.
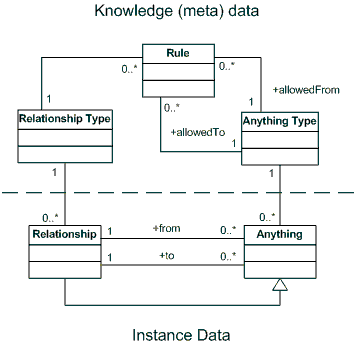
Note that relationships themselves are anythings. This means that relationships may be related to one another. This results in headache inducing power, flexibility and complexity of the resulting system.
Putting it all together
We can combine the concepts of anything, attribute and relationship into one single master pattern. I believe that any domain specific problem could be solved using this ERD.
Notice that Anything = DescribedObject and AnythingType = DescribedObjectType.
It may be possible to replace Generalisation with Rule but I have left both entities in for completeness.
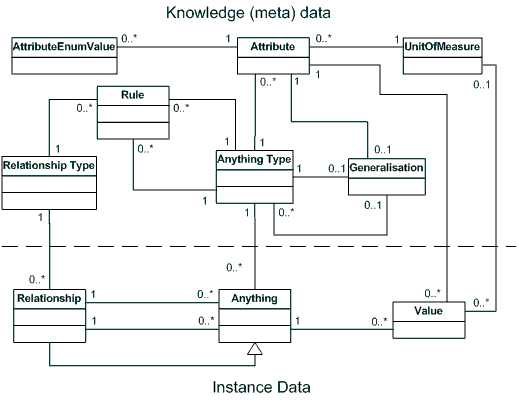
A modelling problem
So, technically, if an undergraduate database modelling student drew this diagram they would have to get 100%, no matter what the case, because the model is generic enough to handle all cases, yes? Well, no. In order to get 100%, the student would also have to provide all the meta data.
Modelling languages such as ER modelling allow us to draw a diagram representing the specific domain being modelled. One will soon discover, after using a pattern such as the above, that you need a second diagram which actually represents the meta data stored in the meta tables.
We should always be suspicious of data models that have the words “entity” (anything), “relationship” or “attribute” in them. That is what the ER modelling language itself was designed to model after all (Wand & Weber, 1999).
If you take the modelling even further, you will realise that it is possible to meta-model this pattern as a reflection of itself. Firstly by discovering that Attributes are simply 1 to 1 relationships between entities and secondly by discovering that simce the meta model can be drawn in an ER model, it can represent itself. This can go on over and over until everything you need to model any application can be stored in two tables.
I have not tried this but I believe it to be possible.
Constraints
This problem begs the question: what exactly is the database management system doing in the above case? The DBMS is usually responsible for maintaining relational integrity and other forms of integrity through the use of constraints. If all the meta data is stored in the database itself as tables, how is the DBMS going to be able to enforce them? The truth is, it can’t. So, the business logic of the actual application will have to enforce these constraints. Some may argue that this is a good thing. I am not so sure. The database is far more capable of enforcing constraints than business logic code.
Of course I don’t mean we should wait for the database to throw an exception every time we try insert a nonsense bit of data, constraints should be checked at the application level as well, I am, however questioning the logic of storing the meta data as tables in the database when the meta data is often freely available by querying the DBMS’s own meta data (for example, SQL server has the sys* views).
Queries
One of the appeals of a relational database is the powerful set manipulation and optimisation that is available. Imagine trying to run the following query: “Find the names of all parts that have a diameter of 10 and a length of 20”.
In a “normal” schema, the SQL statement would be something like:
SELECT Name FROM Part WHERE Diameter = 10 AND Length = 20
In the super flexible schema described above, the statement would be more like:
SELECT Distinct Anything.Name FROM Anything
INNER JOIN AnythingType ON Anything.AnythingTypeID = AnythingType .ID
INNER JOIN Attribute ON Attribute.AnythingTypeID = AnythingType .ID
INNER JOIN Value on Anything.ID = Value.AnythingID AND Attribute.ID = Value.AttributeID
WHERE
AnythingType = 'Part' AND
((Attribute.Name = 'Diameter') AND (Value.ValueNumeric = 10)) AND
((Attribute.Name = 'Length') AND (Value.ValueNumeric = 20))
AND EffectiveDate < GetDate() AND ExpirationDate > GetDate()
Notice that we have to use a “distinct” in the above statement. Because of the higly normalised nature of the schema, all of the joins we do causes us to return more than one row for each part.
Also, to be most correct we have joined Anything to Attribute through the AnythingType entity. This is to ensure that we only get the attributes that are allowed on the “Part” Entity through the metadata.
Why should we care? Surely databases are capable of executing these queries and the queries themselves can be generated by the computer as well. My objection is that by doing this we are perverting the original design of relational databases.
What is the solution?
Using the meta patterns described above is not a feasible solution. They do serve a purpose, however. They point out large deficiencies in relational database management systems as well as ER modelling itself. They are the “desire lines” of the database modelling community. The solution is not to squeeze these OO concepts into existing databases but to rather extend the capabilities of existing databases where it is possible.
Also, I think OR/OO database research has gone in the wrong direction: electing to simply introduce Object Oriented concepts to relational databases and not addressing the actual limitations inherent in relational databases themselves.
What I believe is needed is “database reflection”. Programmers don’t go around writing attribute classes in their code. For those rare cases where the programmers need to flexibly access the meta data of their classes, they use reflection. The same could be done with relational databases.
Below is a list of the deficiencies we can identify in relational databases from this discussion:
- Insensitive to the history of values
- Do not allow for proper reflection of metadata
- Changing the schema on the fly is cumbersome and often discouraged
- Tuples do not have unique identity
- No support for inheritance
Below are limitations of ER modelling in general, based on this discussion:
- Cannot model multi-valued attributes
- Cannot model inheritance
If we managed to solve these problems, we would remove the need to twist ER modelling languages (and thus rtelational databases) to do what we want.
References:
- Wand, Y., Storey, V., & Weber, R. (1999). An ontological analysis of the relationship construct in conceptual modeling. ACM Transactions on Database Systems, 24(4), 494 – 528.
- Michael R. Blaha, Cheryl Smith: A Pattern for Softcoded Values. IEEE Computer 35(5): 28-34 (2002). The idea here is that in order to allow for flexibly adding and removing attributed from entities over time, you model the meta data surrounding attributes and entities themselves.